




Dokumentenklassifikation
In dieser Wikiseite werden die Kernthemen des Tutoriums "Mustererkennung / Klassifikation von Textdokumenten" vom SS18 in angepasster Form behandelt um die vermittelten Informationen für spätere Studiengänge zu erhalten.
Das Tutorium hatte zur Aufgabe, ausgewählte, meist prüfungsrelevante Inhalte der Vorlesung "Mustererkennung" anhand des praktischen Beispiels der Dokumentenstrukturanalyse zu erklären, um das Lernen zu vereinfachen.
Was ist Dokumentenklassifikation?


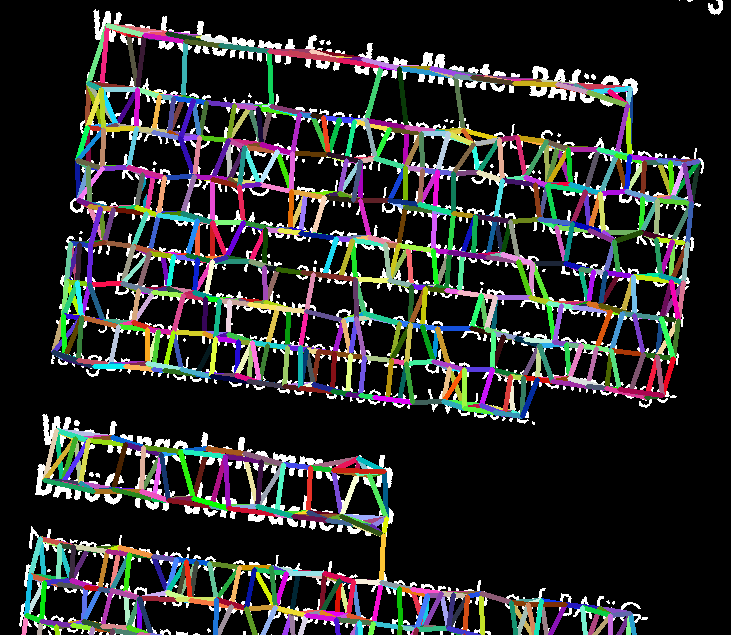



Einige Arbeitsschritte der Dokumentenstrukturanalyse visualisiert. Links nach rechts: Ausgangsdokument, Connected Components Algorithmus, K-Nearest-Neighbor Algorithmus, Textlinienerkennung, Begradigung, Textblockerkennung Quelle: Eigenes Programm, Beispieldokument: Broschüre des BAföG-Amts.
Der Ausgangspunkt der Dokumentenklassifikation ist ein normales Papierdokument. Sie hat zum Ziel, dieses Dokument zu "verstehen" und anhand dieses Verständnisses Schlussfolgerungen über Art und/oder Inhalt zu treffen. Dabei wird die gesamte Prozesskette der Mustererkennung angewendet: Die Daten müssen in geeigneter Form aufbereitet werden, diskriminierende Merkmale müssen gefunden und extrahiert werden und anschließend werden die Merkmale durch einen geeigneten Klassifikator klassifiziert.
Um eine Klassifizierung vorzunehmen, wird in diesem Fall ein Lernalgorithmus angewendet. Es wird eine bereits vorgelabelte Lernstichprobe genommen und anhand dieser Informationen kann der Algorithmus die Merkmale der verschiedenen Klassen lernen. Ist der Klassifikator trainiert, können unbekannte Daten von ihm mit einer gewissen Genauigkeit richtig zugeordnet werden. Die Erfolgsquote ist dabei immer von der gesamten Prozesskette abhängig.
Die Aufgaben der computergestützten Intelligenz
Zu den Aufgaben der computergestützten Intelligenz gehören folgende:
Die Klassifikation:
Die Klassifikation hat zum Ziel, dass der Merkmalsraum auf eine diskrete Menge abgebildet wird (x --> k). Im Beispiel der Dokumentenverarbeitung bedeutet es, dass beispielsweise anhand der Strukturdaten Aussagen über die Art des Dokuments getroffen werden. Also Strukturdaten --> Aussage wie "Brief" oder "Rechnung".
Das geschieht durch das überwachte Lernen. Überwacht bedeutet hierbei, dass gelabelte Daten vorliegen. Also ein Experte hat bereits im Vorfeld zu den jeweiligen Strukturdaten die Dokumentart vorgegeben. Somit haben wir Datenpaare (x, k), die dann vom Programm gelernt werden und je nach Erfolg kann dieses dann neue Daten klassifizieren.
Das Clustering:
Das Clustering ähnelt stark der Klassifikation. Die Hauptunterschiede sind, dass nicht auf ein Klassenlabel k, sondern auf eine Clusternummer g abgebildet wird und es ein unüberwachtes Lernen ist. Das bedeutet, es sind nur die Merkmalsvektoren gegeben, keine label. Gelernt wird dabei, indem auf Ähnlichkeit geprüft wird und ähnliche Daten zu einem Cluster zusammengefügt werden.
Die Regression:
Die Regression lässt sich am einfachsten durch das Beispiel der Börsenspekulation erklären. Anhand der Daten aus der Vergangenheit versucht ein Programm Prognosen für die Zukunft aufzustellen. Es werden Abhängigkeiten der Merkmale gelernt.
Die Assoziation:
Bei der Assoziation werden Daten, die eigentlich nichts direkt miteinander zutun haben auf Verbindungen überprüft. Beispielsweise der Zusammenhang zwischen Arbeiterzufriedenheit und deren Leistung. Beides sind verschiedene Merkmalsvektoren und können doch miteinander verknüpft sein.
Die Prozesskette der Mustererkennung
Signalwandlung:
Wir haben eine physikalische Größe, z.B. ein Papierdokument, und möchten daraus ein analoges Signal erzeugen. Das geschieht z.B. mithilfe von Sensoren und in unserem Fall durch einen Scanner.
Digitalisierung:
Das analoge Signal muss zu einem digitalen gewandelt werden. Dies geschieht meistens über Abtastung oder wie in unserem Fall durch Rasterisierung.
Vorverarbeitung:
In der Vorverarbeitung werden die digitalen Signale verbessert, z.B. durch Filterung, Normierung, Kodierung, etc. Am Ende der Vorverarbeitung sollen alle Daten gleich behandelbar sein. Im Falle der Dokumentenverarbeitung würden die Daten in ein Bildformat wie PNG kodiert werden, dann werden Fehler wie Kaffeeflecken oder Rauschen bereinigt und das Bild begradigt und auf eine einheitliche Größe gebracht.
Merkmalsextraktion:
Nun werden Merkmale bestimmt, die aus den Daten gezogen werden sollen. Hierbei ist es wichtig, die richtigen Merkmale zu finden, die für den jeweiligen Zweck benötigt werden. Im Falle der Dokumentenverarbeitung wäre es z.B. die Extraktion der Strukturdaten des Dokuments.
Als letzter Schritt werden die Merkmale mit einem geeigneten Klassifikator auf eine bestimmte Anzahl Klassen abgebildet. Für den Anwendungsfall, dass die Art von Dokumenten bestimmt werden soll, würden beispielsweise die mit Klassenlabels versehenen Strukturen verschiedener Dokumenttypen gelernt werden und anschließend könnte das dabei entstehende neuronale Netz neue Dokumente zuordnen.
Postulate
Es folgt eine Beschreibung einer Auswahl von Postulaten.Was ist ein Postulat?
Ein Postulat beschreibt etwas, das nicht beweisbar ist und doch als unabdingbares Fundament für weitere Theorien gebraucht wird.Postulat:
„Für ein Analysegebiet lässt sich eine repräsentative Stichprobe finden. Jedes Element der Grundgesamtheit muss gleiche Chancen haben, in die Stichprobe aufgenommen zu werden.“
Dieses Postulat lässt sich mit einem Beispiel aus der Dokumentenanalyse erläutern:
Nehmen wir an, dass Rechnungsdokumente automatisch verarbeitet werden sollen. Dazu muss ich meine Prozesskette an einer Stichprobe testen.
Rechnungen gibt es in allen möglichen Ausführungen. Die Rechnungen unterschiedlicher Firmen unterscheiden sich meist. Würde ich jetzt mit einer Stichprobe von Rechnungen von nur wenigen unterschiedlichen Firmen lernen, kommt es sehr wahrscheinlich zu Fehlern bei den anderen Firmen. Deshalb muss jedes Element der Grundgesamtheit die gleichen Chancen haben.
Der zweite Aspekt des Wortes repräsentativ ist, dass die Stichprobe auch einen gewissen Umfang aufweisen muss. Es gibt dabei keinen festen Wert, da sich die Menge von Anwendungsfall zu Anwendungsfall unterscheidet und unter anderem abhängig von der Art der Merkmale ist. Generell gilt jedoch, dass mehr Daten besser sind.
Postulat:
"Ein komplexes Muster lässt sich in einfachere Bestandteile zerlegen, die untereinander in strukturellen Beziehungen stehen."
Dieses Postulat ist ebenfalls einfach am Beispiel von Dokumenten erklärt. Betrachte ich das Dokument als Muster an sich, ist es schwierig zu verarbeiten, da ich außer den rohen Bilddaten keine wirklichen Informationen habe. Ich kann es durch verschiedene Algorithmen aber immer weiter in seine Bestandteile zerlegen:
- Das Dokument wird definiert aus Dokumentstrukturblöcken, die zueinander in einer Beziehung stehen. (Überschrift, Textblock 1, Textblock 2, ... , Bild, Grafik, Adresse)
- Diese Strukturblöcke lassen sich ebenfalls zerlegen. Die Textblöcke beispielsweise bestehen aus Textzeilen.
- Die Textzeilen bestehen aus Wörtern
- Die Wörter bestehen aus Buchstaben
- Die Buchstaben bestehen aus Pixeln
Postulat:
„Komplexe Muster lassen sich meist durch relativ wenige einfachere Bestandteile darstellen. Eine beliebige Auswahl dieser führt nicht zu Mustern.“
Stellen wir uns erneut das komplexe Muster Dokument als digitales Bild vor. Die relativ wenigen Bestandteile sind beispielsweise die schwarzen Pixel auf einem schwarz-weiß-Dokument. Sie alleine beschreiben dieses komplexe Muster, auch wenn sie nur einen geringen Gesamtanteil am Dokumentenbild haben.
Würde ich zufällig schwarze Pixel auf einen weißen Hintergrund streuen, würde dies kein Dokument erzeugen, sondern lediglich ein rauschen. Deshalb führt eine beliebige Auswahl der einfachen Bestandteile nicht zu Mustern.
Die Vorverarbeitung
Die Vorverarbeitung beschäftigt sich mit der Aufbereitung der Daten für die Weiterverarbeitung.
Ihre Ziele sind:
- Verarbeitbarkeit: Die Ausgangsdaten sollen in einer weiterverarbeitbaren Form gespeichert werden.
- Konsistenz: Die Datensätze sollen vollständig und widerspruchsfrei sein.
- Vereinfachung: Die Daten sollen nach Möglichkeit vereinfacht werden um die Streuung im Musterraum zu verringern.
- Selektion: Es sollen nur für den Anwendungsfall relevante Daten verarbeitet werden.
- Eliminierung: Fehlerbehaftete oder unnötige Daten sollen verworfen werden.
- Korrektur: Wenn die Möglichkeit besteht, sollen fehlerhafte Daten korrigiert werden.
- Skalierung: Die Vergleichbarkeit der Daten soll ermöglicht werden.
Diese Zielstellungen bestmöglich zu erfüllen ist ein essentieller Schritt für die Mustererkennung. Wird an fehlerhaften oder schlechten Daten gelernt, verschlechtert sich das Endergebnis. Eine saubere Vorverarbeitung zu ermöglichen kann deshalb sehr viel Zeit in einem Mustererkennungsprojekt in Anspruch nehmen. Leider lässt sich schlecht Bewerten, wie gut eine Vorverarbeitung ist, da die Ergebnisse von der gesamten Prozesskette abhängig ist. Jedoch können Expertenschätzungen, Parametervariationen und heuristische Bewertungen dafür einen Anhaltspunkt liefern.
Eine Beispiel der Vorverarbeitungsschritte in der Dokumentenanalyse:
- Einscannen des Papierdokuments
- Abspeichern in geeignetem Bildformat
- Umwandeln digitaler Dokumente in selbiges Format
- Änderung der Kodierung von Farbkodierung auf Graustufen
- Thresholding
- Begradigen des Dokuments
- Skalierung der Bilder auf einheitliche Größe
- Entfernen von Rauschen und anderen Verunreinigungen des Dokuments
- Extraktion der Strukturblöcke
- Vereinheitlichung und Filterung der Strukturblöcke
Die Extraktion und Verarbeitung der Merkmale
Die Aufgabe der Merkmalsextraktion ist es, den höherdimensionalen Musterraum auf einen möglichst niedrigdimensionalen Merkmalsraum abzubilden. Dieser Merkmalsraum bezeichnet praktisch das, was für den Anwendungsfall von Interesse ist.
Möchte ich beispielsweise Dokumente aufgrund ihrer Struktur klassifizieren können, beinhaltet der Merkmalsraum die Lagebeziehungen und Arten der Strukturblöcke.
Die Merkmalsextraktion nutzt die aufbereiteten Daten der Vorverarbeitung um die relevanten Merkmale zu finden und zu extrahieren. Das schwierigste ist, geeignete Merkmale für den Anwendungsfall zu finden. Man sucht möglichst diskriminierende Merkmale.
Ein Beispielproblem dafür wäre das Erkennen von Textblöcken. Wir haben einen Datensatz aus verschiedensten Blöcken: Texte, Bilder, Logos, Grafiken, ... . Die Blöcke sind als Bild vorhanden. Es ist schwierig, in dem Fall ein entscheidendes Merkmal zu finden. Es gibt aber eines: Textblöcke zeichnen sich dadurch aus, dass sie aus Textzeilen bestehen. Diese verlaufen horizontal und zwischen ihnen ist immer ein gewisser Zeilenabstand. Bei den anderen Blöcken ist das nicht der Fall. Man kann nun das zweidimensionale Bild auf ein eindimensionales Signal abbilden, indem man in jeder Bildzeile die Farbwerte mittelt. Heraus kommt ein Sinusähnliches Signal bei Textblöcken, welches das diskriminierende Merkmal ist.
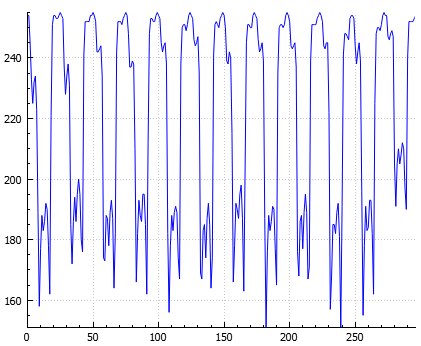
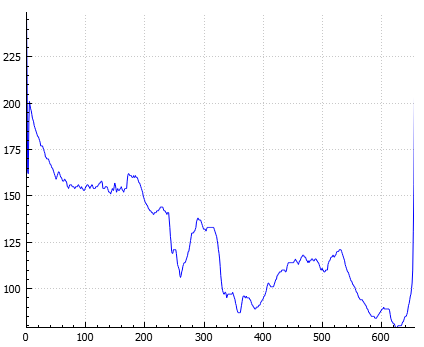
Eindimensionales Signal eines Textblocks (links), Eindimensionales Signal eines Bildblocks (rechts). Quelle: Eigenes Programm
Die Nächste-Nachbarn Klassifikation "NN" und ihre Erweiterung "k-NN"
Die Nächste-Nachbarn Klassifikation ist ein lokaler einfacher und schneller Klassifikator.
Er klassifiziert, indem er von einem Merkmalsvektor ausgehend die Distanzen zu allen anderen Merkmalsvektoren berechnet und ihm die Klasse des Nachbarn mit dem geringsten Abstand zuweist.
Die Erweiterung um den Parameter k erlaubt eine etwas komplexere Zuordnung. Der Parameter bestimmt dabei, wie viele der nächsten Nachbarn betrachtet werden. Ist der Parameter k beispielsweise 5, werden die Klassenlabels der 5 nächsten Nachbarn verglichen und das häufigste Label wird für den Merkmalsvektor übernommen.
Wichtig für die Nächste-Nachbar Klassifikation ist das geeignete Distanzmaß. Dieses unterscheidet sich je nach Anwendungsfall. Man bezeichnet ihn als lokalen Klassifikator, weil er Klassenlabels rein anhand der nächsten Punkte oder des nächsten Punktes zuordnet.
Der Nachteil dieser Form der Klassifikation neben seiner Einfachheit ist, dass die gesamte Lernstichprobe verglichen werden muss. Es gibt allerdings Möglichkeiten, dieses Problem zu umgehen, zum Beispiel indem man die Lernstichprobe durch klassentypische Merkmalsvektoren ersetzt.
Diese Seite wurde noch nicht kommentiert.